Why we open sourced our uptime monitoring system
About a month ago, Sourcegraph released Checkup, an open source, self-hosted uptime monitoring system written by Matt Holt.
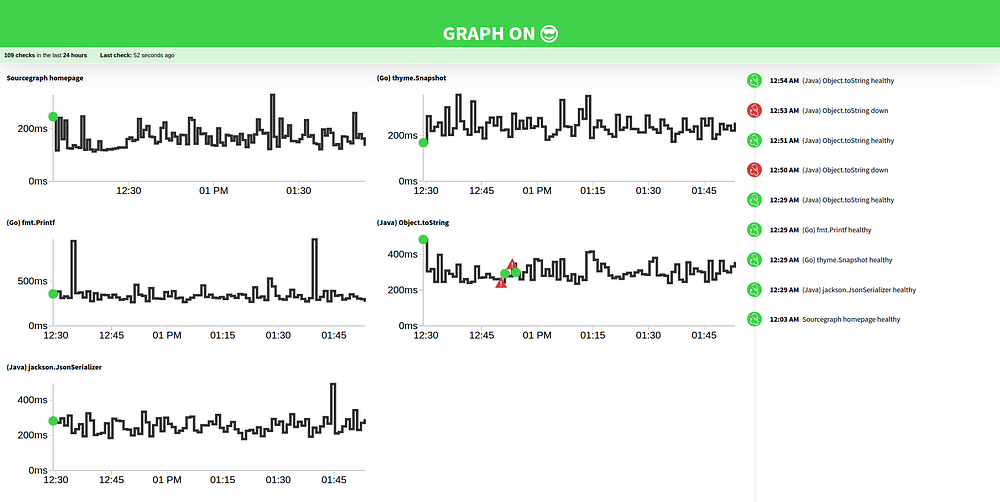
Following its release, a lot of people asked us how we were using Checkup at Sourcegraph. Today, we’re sharing our public status page, powered by Checkup, and laying out some of the big advantages we’ve found using an open source health check tool.
Why yet another uptime tool?
We sponsored the creation of Checkup, because we found none of the existing paid or free uptime monitors met our needs. You can read the Checkup launch post for details, but here’s a quick overview of some of the things it enables:
- Define checks in code instead of via GUI: A lot of other uptime services require you to define your health checks manually using slow, clunky interfaces.
- Keep health checks up-to-date: Before Checkup, we found that it was easy for our health checks to fall out of date, because they were stored outside our codebase.
- Useful for both public and private services: You can’t use SaaS uptime monitors for services that aren’t publicly accessible on the Internet.
- No black-box downtime: Uptime services themselves can sometimes go down and when the source and production environment are not available, it can be hard to understand why.
How Sourcegraph uses Checkup
Using an open source health check system makes it possible to incorporate health checks into a few different stages in the software development cycle.
1. Uptime monitoring
The first and obvious use case is production health checking. This is what you see on checkup.sourcegraph.com. Checkup is easy to deploy and all the monitoring data is stored in S3, so it’s easy to audit. And you can geographically distribute checks by deploying to servers in different parts of the world — anywhere where you can spin up a VPS.
2. Continuous integration
Though typically viewed as a last line of defense in production, health checks are really no different from any other test you’d like to run against your app. And as experienced software engineers know, it’s far better to catch a bug in test than in prod.
Because Checkup can be used as a simple CLI, you can roll it into your continuous integration scripts. Below is a snippet taken from Sourcegraph’s CI build that demonstrates this ability. We version a checkup.json file directly in our codebase that describes critical URLs that we must not break.
#!/bin/bash
# Quick end-to-end uptime tests
checkup_success=false
src serve & # run an instance of our server
for i in {1..5}; do
sleep 2s;
echo "Checkup health checks (attempt $i / 5)";
if (checkup -c ./dev/ci/checkup.json); then
checkup_success=true;
break;
fi;
done;
kill %1 # kill the instance of our server
if ! "$checkup_success"; then
echo "Checkup health checks failed after 5 attempts" && false;
fi
3. In development
What’s better than a test you can run in CI? Why, a test you can run in your dev environment, of course. Before we push a new version of Sourcegraph and kick off a CI build, we can run Checkup against a dev server to verify that all critical endpoints are live. All you need to do is run “checkup” in the terminal (it picks up the endpoints from the configuration file versioned with the code).

Why source accessibility is important
We think Checkup has a lot going for it as a health check tool. It’s not for everyone, but its simplicity and developer-driven design suit our purposes well. Besides the feature set and simple interface, we think Checkup has another strong advantage: its source code is publicly available.
Having the source available means you can dive into the inner workings of Checkup if unexpected behavior crops up. And you can extend the tool to fit your needs (and push those changes upstream to share those capabilities with other Checkup users). Already, community contributors have added support for new underlying data stores and new types of checks (TCP and DNS).
But availability alone is not enough. There are plenty of open source projects where the code is available but inscrutable. Documentation and API design are key, but so is making the code itself as easy to navigate as possible. And in that spirit, here are 5 different places where you can dive into the Checkup source and understand how it all works:
- The main function. This is where it all begins. Like many main functions, ours is simply a wrapper around a method call…
- RootCmd.Run(). Checkup’s “true” main function. We use spf13's Cobra library, which lets you define a CLI by creating an instance of the cobra.Command struct.
- checkup.Checkup is the type around which everything revolves. It has methods that run the health checks, gather the results, and store the data.

- checkup.Storage is the interface you implement to create a new type of data store (e.g., if you wanted to store the data in Google Object Store instead of S3 or local disk).
- checkup.Checker is the interface you implement to create a new type of health check.
We hope you’ll find Checkup useful as a tool and informative as a codebase. Please send us feedback and let us know how you’re using it!