The find-and-replace Odyssey, a programmer's guide
So much of what we do as programmers boils down to automating the tedium out of our work. We'd like to spend our lives focusing on the design of beautiful abstractions and algorithms, but before we can get to that, we have to do the dirty work—and do it quickly.
Whether you are a newbie or a seasoned engineer, chances are that you struggle with day-to-day tasks that seem to take longer than they should. One such recurring challenge is find and replace.
Find and replace encompasses a huge variety of renames, refactors, and transformations that you might want to apply in code. To name just a few examples:
- Making a change to a public API and updating downstream consumers
- Changing a function signature and updating every call site
- Converting a bunch of data in one format to another (e.g., XML to JSON)
- Identifying and fixing common anti-patterns to improve code quality
Doing any of these by hand would be mind-numbing. For assistance, you can turn to a wide variety of find-and-replace tools. But there are so many tools, with varying degrees of applicability, expressivity, ease-of-use, ease-of-learning, and scalability. How do you pick the right one and where do you begin?
You may go through a progression like this:
|
You start with manual find-replace, maybe with some regex in your editor. |
|
You bite the bullet and finally learn grep and sed,
so you're no longer constrained by the bounds of your editor.
|
|
You get annoyed wth grep and sed and find
tools like ripgrep (rg) and codemod.
Maybe you dive down the rabbit hole of parsers. Powerful—but it's a slog reading AST specs and writing tree traversers.
|

|
In your quest for ever greater efficiency, you discover comby, an awesome new pattern-matching language for code.
You use it to execute really really large crucial changes across your organization's code.
|
In this post, we'll cover all the legs of this journey. If you're new to all this, you'll get an introduction to many tools that you can use to slay monsters of tedium along your programming journey. If you're already a veteran Odysseus, feel free to skip to the last two parts of this post, covering Comby and large-scale code change campaigns.
Here's what we'll cover:
Find and replace in your editor
Most code editors offer some sort of find-and-replace facility. At the most basic level, you have
literal string substitution. This enables you to find instances of foo and replace them with
bar.
However, there are many cases where you want to apply a general change pattern, not just replace one word with another. Adding arguments to a function, fixing a common anti-pattern, standardizing library usage, and transforming data from one format to another—these call for a tool that can express patterns of transformation.
Regular expressions
The most commonly used pattern-matching language is Regular Expressions, commonly abbreviated as
"regex".1 Most code editors support regex searching, and it is commonly toggled on using a button
or icon with the .* symbol.
With regexes, you can do stuff like this:
| Description | Regex | Match | Does not match |
|---|---|---|---|
| Find all symbol names starting with "foo" | foo\w* |
fooBar | barFoo |
| Find all characters between double quotes | "[^"]" |
"hello world" | hello world' |
| Find all references to fields of a certain variable | base\.\w+ |
base.Path | basePath |
There are different dialects of regex. In this post, we'll use POSIX Extended Regular Expressions. For those who are unfamiliar with it or who need a quick refresher, here's an overview of the syntax:
- Alphanumeric characters are generally interpreted literally.
*means "zero or more of the preceding character".+means "one or more of the preceding character".?means "zero or one of the preceding character".-
[...]matches a single character in a character set. For example[ABC]matches either "A", "B", or "C".[A-Za-z]matches any upper- or lower-case letter.[^...]matches any character not in the set. Many shorthands for character classes also exist:.matches any alphanumeric character. To match a literal period, use\.\wmatches any alphanumeric character or underscore. It is equivalent to[A-Za-z0-9_].\Wmatches any non-alphanumeric character.\smatches a single character of whitespace (e.g., spaces or tabs).\Smatches any non-whitespace character.\bmatches a word boundary.
- You can also group parts of your regex with
(...). These groups are treated as single units, so(ABC)+will matchABC,ABCABC, andABCABCABC.
Regex has a notion of capturing groups for find-replace operations. Capturing groups capture part of the overall match so they can be referenced in a replacement pattern. For example, here's a regex and replacement pattern that will reverse the order of arguments in a function call:
| Input → Output | myFunc(foo, bar) → myFunc(bar, foo) |
|---|---|
| Regex | myFunc\((\w+), (\w+)\) |
| Replacement pattern | myFunc(\2, \1)2 |
In the regex above, the literal parens are escaped \(\) while the unescaped parens () capture
the parts of the match that correspond to the arguments to the function.
One thing to note about regex is the abundance of special characters. All these characters have
special meanings: (, ), [, ], ., $, ^, +, ?, |. This means you'll need to escape
them with \ if you want to literally match these characters. This wouldn't be so bad were it not
for the fact that all these characters also occur abundantly in code. This means that your regex
will often include many escape sequences. Add grouping into the mix and very soon you'll end up with
something quite unreadable.
To alleviate this readability issue, there are a number of regex visualizers you can use to understand what's going on:
Even with visualization, however, regexes are often difficult to read and write. It may take multiple attempts and a debugging session to arrive at the correct incantation that properly expresses the find-and-replace pattern you'd like to apply.
Keyboard macros and multiselect
One way to address the readability issues with regexes in your editor is to use keyboard macros, instead.
Keyboard macros are a feature of some editors (e.g., Emacs, Vim, IntelliJ) that let you record keystrokes and replay them later. If you can describe the change you'd like to make in a set of keystrokes, a keyboard macro can be much easier to execute than a regex find-and-replace.
Let's say we want to add an additional parameter to call sites of the function, errorutil.Handler
(defined in this
file). In
Emacs, I can describe the change I'd like to make in the following keystrokes:
Ctrl-x ( # begin recording the macro
Ctrl-s errorutil.Handler( # search for the pattern
Ctrl-Alt-n Ctrl-b # jump to one character before the end parens
, "default<space>value" # add the default value for the new argument
Ctrl-e # move cursor to end of the line
Ctrl-x ) # finish recording the macroOnce I've recorded the macro, I can replay my keystrokes with C-x e and can hold down e to apply
it repeatedly.
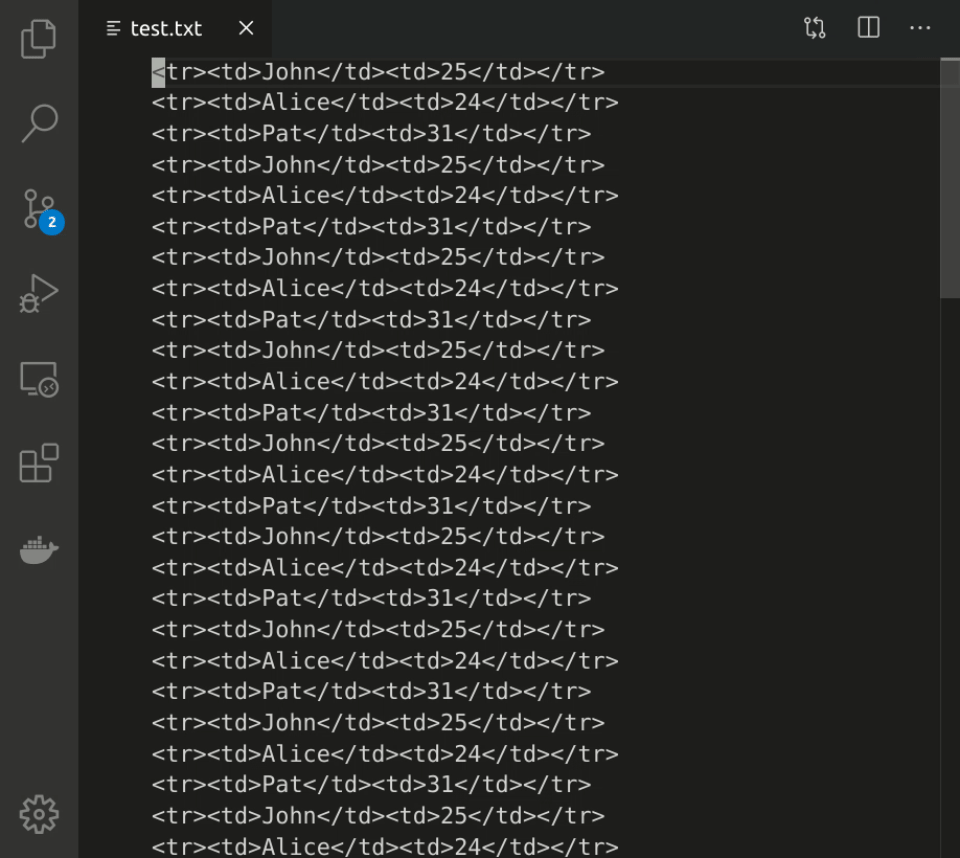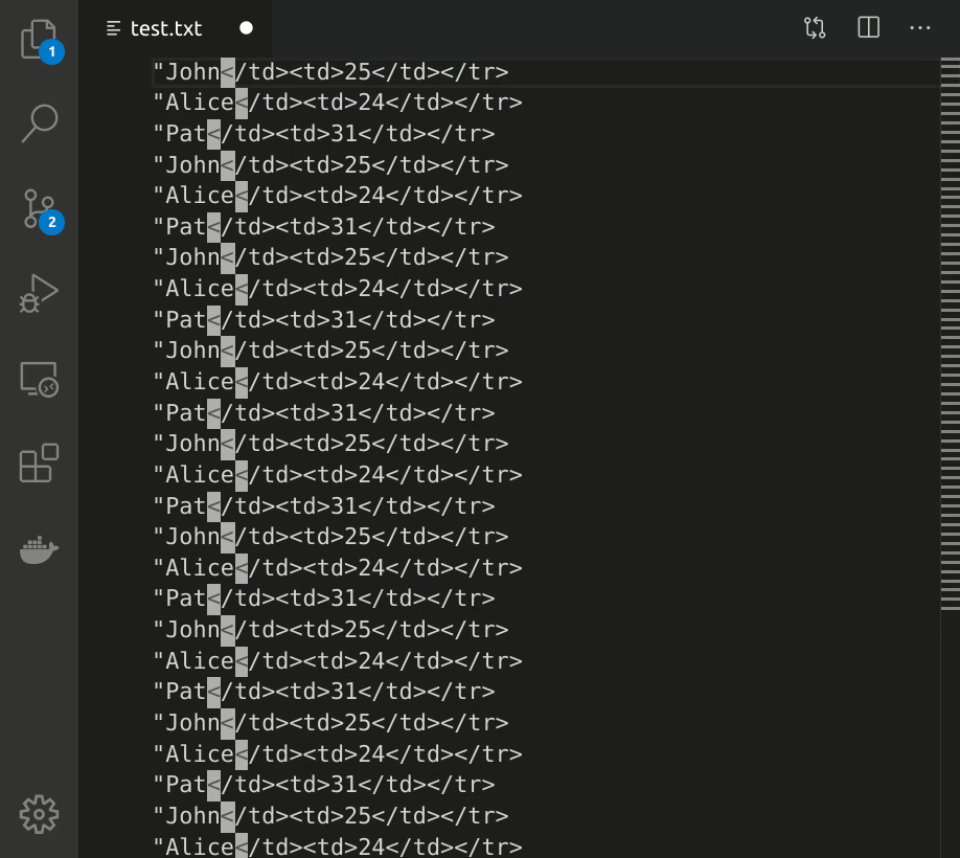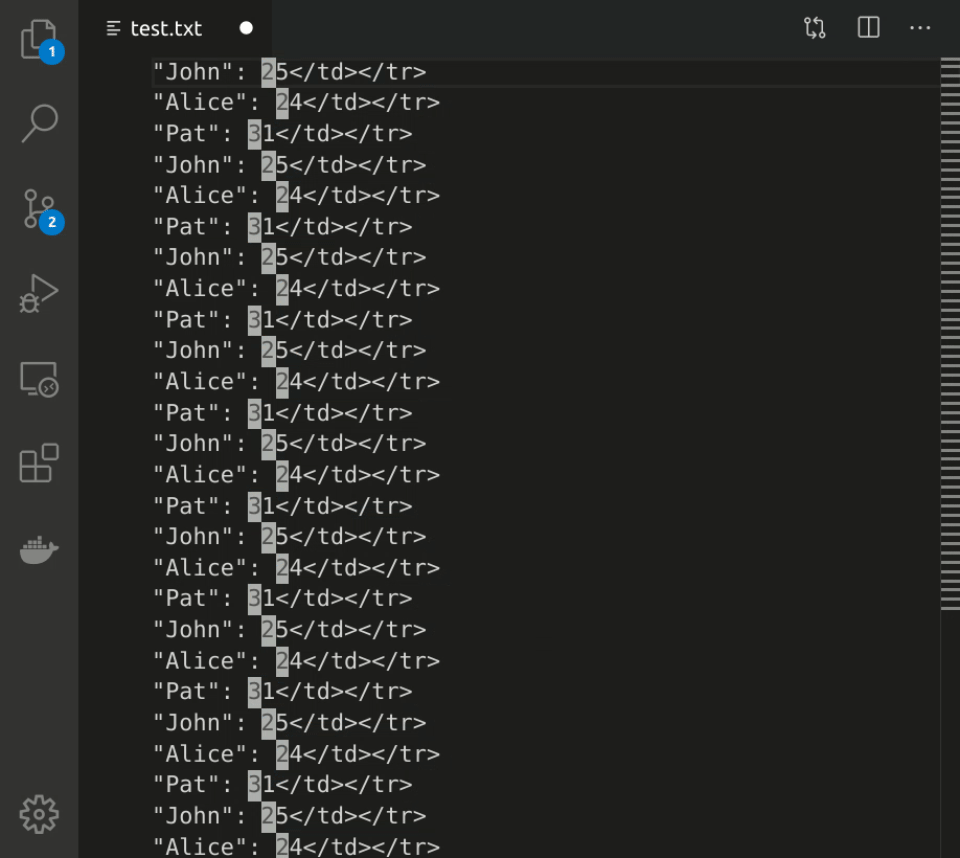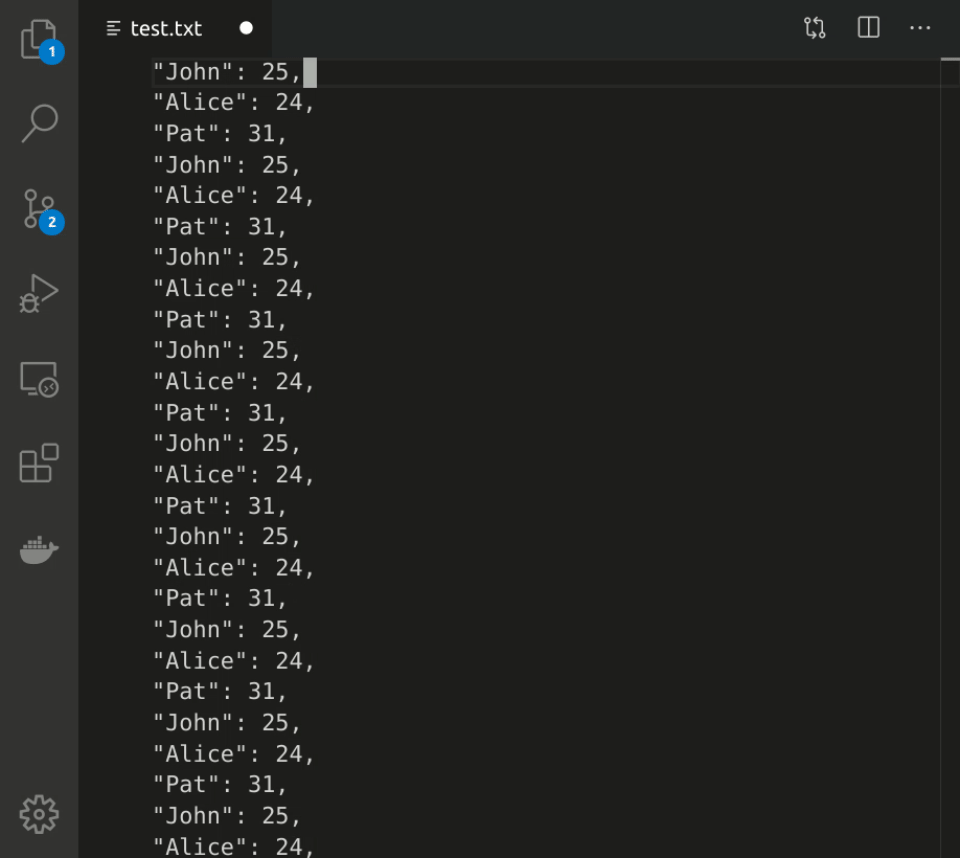
Here's another example involving data transformation. Say you want to turn an HTML table like this:
<table>
<tr><td>John</td><td>25</td><tr>
<tr><td>Alice</td><td>24</td></tr>
...
<tr><td>Pat</td><td>31</td></tr>
</table>into a JSON list like this:
[
{ "name": "John", "age": 25 },
{ "name": "Alice", "age": 24},
...
{ "name": "Pat", "age": 31 },
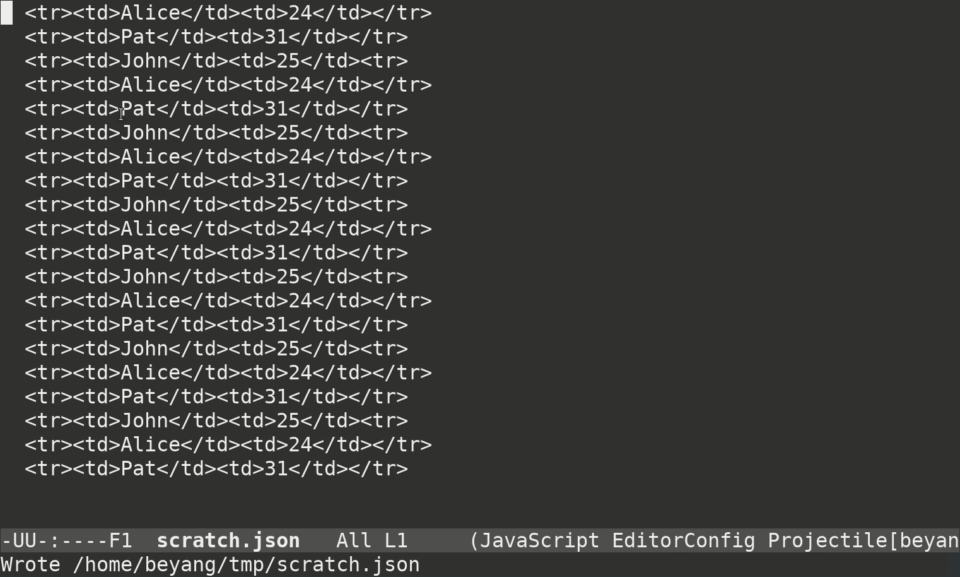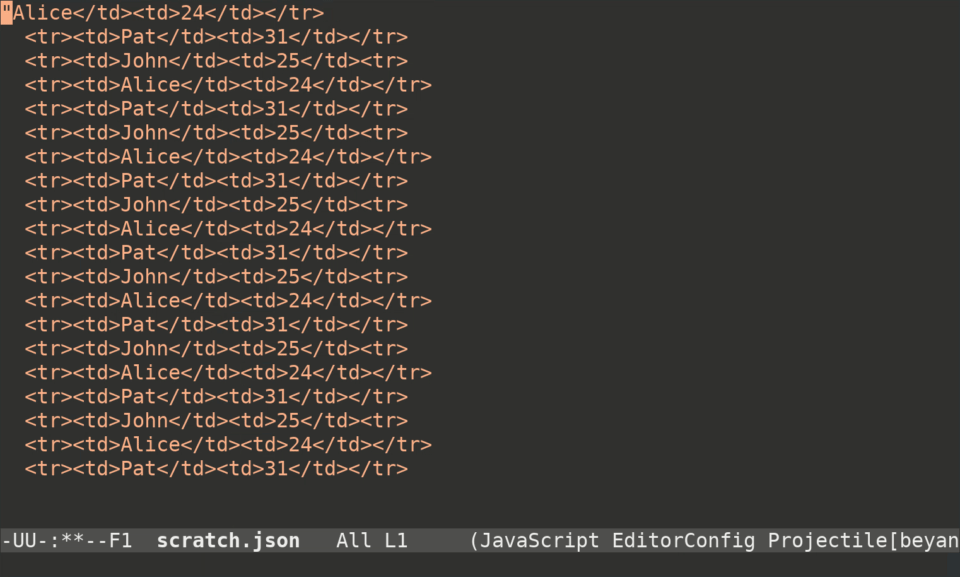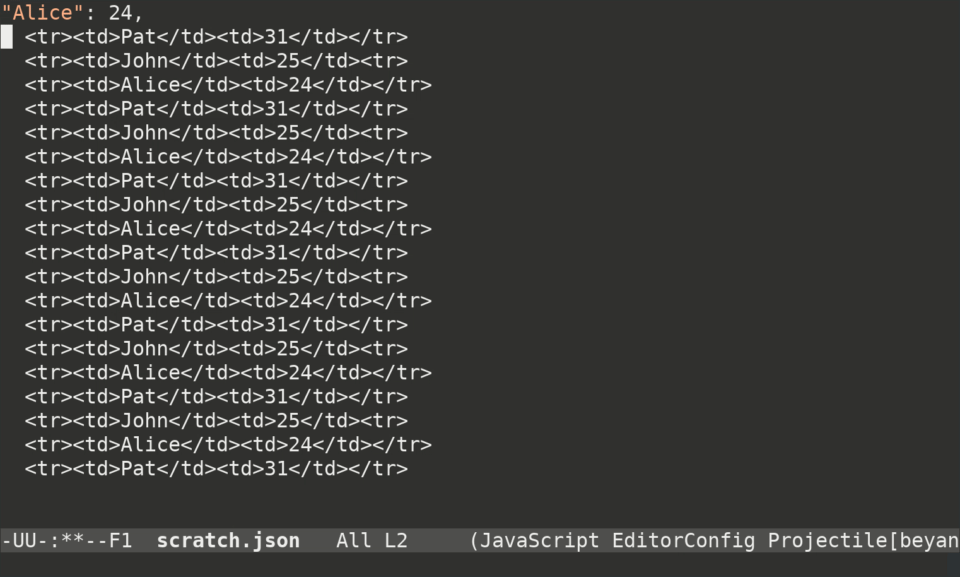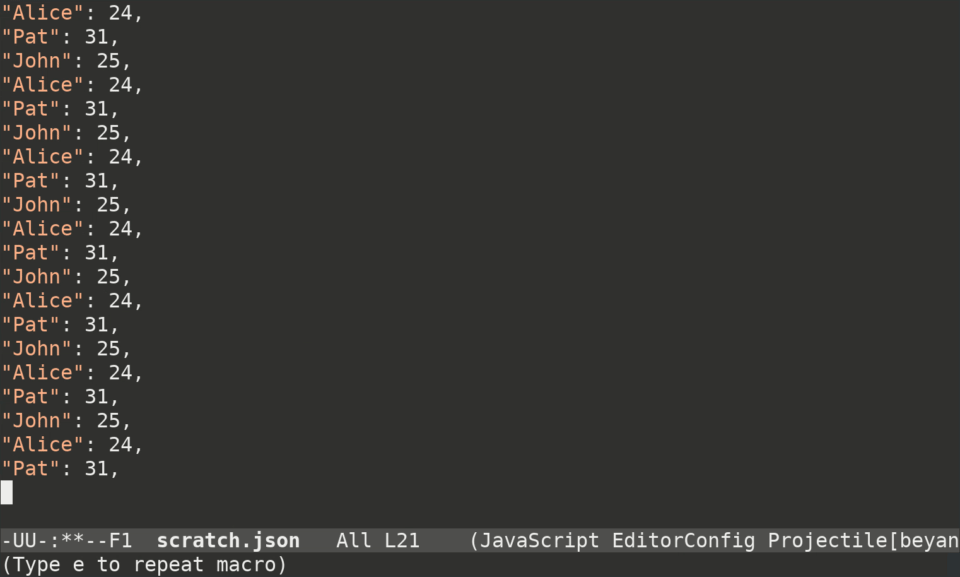
]To do that with keyboard macros in Emacs, you can type this:
Ctrl-x ( # begin recording the macro
Ctrl-s < t d Ctrl-f # move cursor to 'John'
Ctrl-<space> Ctrl-a Ctrl-w # delete everything on the line prior to 'John'
" Alt-f " # put double quotes around 'John'
Ctrl-<space> Ctrl-s < t d > Ctrl-w # delete everything from the end of "John" to '25'
, <space> " Alt-f " <space> , # put quotes around '25' and add a comma
Ctrl-a Ctrl-n # move cursor to the beginning of the next line
Ctrl-x ) # finish recording macroHere's what it looks like in real time:
A related feature of some editors (e.g., VS Code, Sublime Text, IntelliJ) is multiselect, which enables the creation of multiple cursors or selections. Here's a short clip of using multiselect in VS Code tackling the same HTML-to-JSON transformation:
You can do some pretty cool stuff with multiselect.
Both keyboard macros and multiselect are powerful, but they are only supported in some editors. They also work best when the change is relatively simple and is limited to a few files that can be opened in the editor.
Semantic refactoring
Many editors and editor plugins support refactoring code using knowledge of the language semantics. These refactoring capabilities are built using compiler libraries and so achieve a 100% degree of accuracy and precision. The IntelliJ family of IDEs supports semantic refactoring for most of their supported languages. The Language Server Protocol aims to enable an ecosystem of language servers that can provide semantic capabilities across many editors and languages.
You should consult your editor documentation or plugin ecosystem to see if semantic refactoring is supported for your language. Semantic refactoring sometimes goes by different names like "intellisense", "code intelligence", or "structural search and replace".
The downside to semantic refactoring is that it is very specific to the language. A separate integration for each language must be created, which means that frequently the language you're working in may be unsupported in your editor of choice. This is especially true if the language is something like HTML, Shell, or any of the innumerable YAML, JSON, or XML schemas.
Even if the language is supported, the transformations must be described in terms of modifications to the parsed AST. Making arbitrary modifications to the AST requires writing code, which involves a significant time investment. Consequently, semantic refactoring tools often provide out-of-the-box transformations that cover the most common types of refactorings, such as renaming a function or adding an additional parameter. If your transformation fits into one of these ready-made templates, you have an extremely accurate and powerful tool to make broad changes across all the files in your editor workspace. If your transformation does not fall into one of these templates, then you're out of luck.
Find and replace outside your editor
Thus far, we've focused on find-and-replace inside the editor. These features can be very powerful, but they are constrained by what you are able to edit in your editor. There are a number of reasons why you'll have to make code modifications outside your editor:
- Your editor doesn't make it easy to apply the type of transformation you want.
- You might be modifying files in a place where your editor isn't available (e.g., a server).
- You might be applying a change across more files than you want to open in your editor.
- You might want to apply a large-scale change across code that doesn't exist on your local machine.
As a general rule, the larger the universe of code you care about is (whether that universe is a large proprietary codebase or the universe of open source), the more likely it is that you'll need to find and replace outside your editor. To do that, we'll need to add some more tools to our toolbox.
grep and sed
grep3 is a program that scans text files line-by-line and prints each line that matches a
regular expression. sed4 is a tool that matches and transforms text using regular
expressions. Both are extremely versatile and useful tools to have in your programmer's toolbox.
Suppose again you're adding an additional parameter to the errorutil.Handler function
and now need to update all call sites of that function to pass some default value for the extra
argument. You can do that5 in a one-liner with grep and sed:
grep -lRE 'errorutil\.Handler' | xargs sed -i -E 's/Handler\(([A-Za-z0-9_\.]+)\)/Handler(\1, "default value")/'It fits on one line! But it's not the clearest thing in the world, so let's break it down6:
| Part | Description |
|---|---|
grep |
We're using grep to generate a list of filenames that may contain the specified pattern. We'll then feed these to sed to do the actual replacing. This is necessary for performance reasons, as running sed over all the files in your repository will be slow. |
-lRE |
The -l flag tells grep to print only filenames. The -R flag tells grep to do a recursive search in the current directory. The -E flag tells grep to use the extended regex syntax, which we use throughout this post. |
'errorutil\.Handler' |
This is the regex pattern that selects for matches like errorutil.Handler(serveRepoBadge). Note that this regex doesn't have to match the expression we want to replace exactly, because the purpose here is only to filter down to a small enough set of filenames to pass to sed. |
| |
This is a Unix pipe, which forwards the standard output of the previous command to the standard input of the following command. |
xargs |
This is a program that wraps other commands to map standard input to command line arguments. sed takes filenames as command line arguments, and this is necessary to map the output of grep to command line arguments to sed. |
sed |
sed transforms the contents of a file using a regex replacement pattern. |
-i |
This flag tells sed to modify files "in place", rather than printing the transformed contents to standard output. |
-E |
This flag tells sed to used extended regex syntax. |
s/Handler\(([A-Za-z0-9_\.]+)\)/Handler(\1, "default value")/ |
This specifies the replacement pattern and is a bit of a doozy, so let's break it down even further. This is actually an expression in the sed language. s is the "substitute" command. The character immediately after s specifies the delimiter that will separate arguments to s. (In this case, it is /, but we can make it any character we want so long as we're consistent.) The first argument, Handler\(([A-Za-z0-9_\.]+)\), is a regular expression with a matching group to capture the argument to the function call. The second argument, Handler(\1, "default value"), is a replacement pattern, which references the regex capture group with \1. |
If all this is clear as mud, don't worry—you're not alone. grep and sed are powerful tools, but
they're not super beginner-friendly.7 8
ripgrep (rg) is a newer alternative to grep9 that is
faster and has more user-friendly defaults (e.g., you don't need to remember to set flags like
-RE to get the behavior you want). Here's the one-liner above rewritten with ripgrep, instead of
grep:
rg -l 'errorutil\.Handler' | xargs sed -i -E 's/Handler\(([A-Za-z0-9_\.]+)\)/Handler(\1, "default value")/'This is better, but still a little gnarly. A good part of the reason that grep and sed are
considered hard is because regexes are hard.
Codemod
One way to alleviate the pain of finding and replacing with regular expressions is to do it interactively. This is the approach taken by Codemod.
Here's how you would use codemod to add an additional argument to errorutil.Handler call sites:
codemod -m -d . --extensions go 'errorutil.Handler\(([A-Za-z0-9_\.]+)\)' 'errorutil.Handler(\1, "default value")'| Part | Description |
|---|---|
codemod |
The Codemod command. |
-m |
Turns on multiline matching. This is nice, as getting sed to match over multiple lines is a bit of a pain. |
-d . |
Search recursively in the current directory. |
--extensions go |
Restrict search to files ending in .go. |
errorutil.Handler\(([A-Za-z0-9_\.]+)\) |
The "find" regex, with a capturing group. |
errorutil.Handler(\1, "default value") |
The replace pattern. |
When you run the command, codemod will prompt you to accept, reject, or make further edits to each
change:
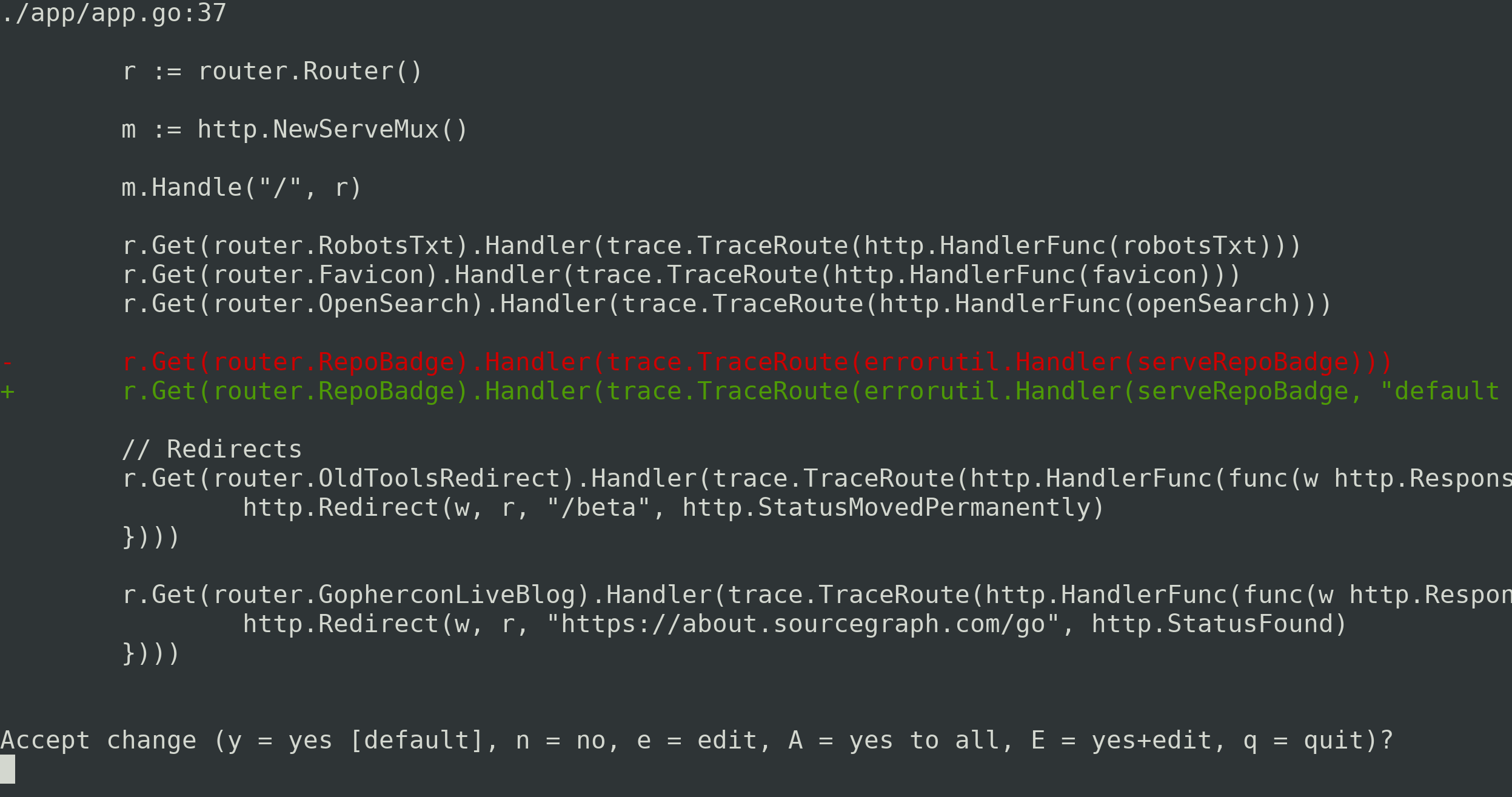
This interactivity is nice, because it's very difficult to write regexes that work 100% correctly on
the first try. If you decide you need to refine the regex, you can exit and codemod will remember
your place, so you can pick up where you left off. You also have the option of manually editing a
given match, which is useful for the handling edge cases where your regex replacement pattern does
the wrong thing.
Codemod also has a Python API for expressing interactive transformations in Python code, which is useful for describing more complex changes:
import codemod
codemod.Query(...).run_interactive()Language-specific tools
Just as certain editors and editor plugins have support for semantic refactoring, there are command-line tools and libraries that support modifying code by transforming the AST.
In the JavaScript world, two popular tools are jscodeshift and recast. Similar tools exist for other languages.
These are fantastic if your change is complex enough to require the full expressivity and type safety of editing the AST.
The downsides are:
- You have to learn a new tool for each language.
- A tool might not yet exist for your language, or it may lack certain features.
- Because you're describing your changes in terms of transformations of the AST, you will probably have to write code and learn the structure of the language's AST.
- Your transformation will have a hard time touching textual parts of the source code that are not represented in the AST. For example, the contents of string literals or comments.
Comby
Another way to alleviate the pain of regular expressions that doesn't require diving off the deep-end into language-specific semantic analysis is to use a textual pattern matching language that's more suited to code.
Comby is a fairly new tool that introduces a simple new syntax for matching common patterns in code. It aims to be both more expressive and more user-friendly than regex in this domain.10
Here is a Comby one-liner that handles adding an extra argument to errorutil.Handler:
rg -l errorutil | xargs comby -in-place 'errorutil.Handler(:[1])' 'errorutil.Handler(:[1], "default value")'| Part | Description |
|---|---|
rg -l errorutil |
Use ripgrep to print names of all code files that contain "errorutil" |
| xargs |
Pipe the filenames to comby |
comby -in-place |
Edit the files in-place with the comby CLI |
errorutil.Handler(:[1]) |
The match pattern, which sub-matches the argument using the Comby hole syntax |
errorutil.Handler(:[1], "default value") |
The replace pattern, which references the sub-matched hole |
Contrast the relative readability of this comby example with the regex we wrote for sed earlier
in this post.
Comby can also express patterns that cannot be expressed in any regex. Consider the following call site:
errorutil.Handler(someOtherFunction(blah))This call site would not be selected by our earlier regular expression, which doesn't account for the nested parens. We could update the regex to account for one layer of nested parens:
errorutil\.Handler\((\w*\(\w*\)|\w+)\)But what if we had double-nested parens, or triple-nested parens? These are perfectly valid in the code, but to accomodate them, we'd have to make our regex longer and longer—and no matter how long we made it, we still couldn't full capture what we're trying to describe.
This difficulty points to a more general limitation of regular expressions: they cannot express
nestable "bookend" patterns of the form <delimiter>stuff<delimiter>. Such patterns are everywhere
in code: string constants ("foo"), function calls (foo(bar())), control blocks (if () {}),
array literals ([]), and more. Regular expressions cannot express these patterns, but Comby makes
it easy.
Here are a few more examples:
| Description | Comby invocation |
|---|---|
| Reverse function argument order | comby 'myFunc(:[1], :[2])' 'myFunc(:[2], :[1])' |
| Convert HTML table to JSON | comby '<tr><td>:[1]</td><td>:[2]</td></tr>' '":[1]": :[2]' |
| Update Go error handling to use wrapped errors | comby 'fmt.Errorf(":[head]%s:[tail]", err)' 'fmt.Errorf(":[head]%w:[tail]", err)' |
Comby's advantages can be summed up in two words: expressivity and ergonomics.
- Expressivity: You can capture patterns that involve nested delimiters, which are inexpressible with regex.
- Ergonomics: Unlike regex, Comby has very few special characters, so Comby patterns are generally more readable and writable.
Comby also supports an interactive mode (using the --review flag) like Codemod, and you can play
around with it in a live demo at comby.live.
Due to its newness, Comby is not yet as widely adopted as regex-based tools like grep and sed,
but it is off to a strong start and I predict it will supplant regex in more and more use cases in
the coming years.
Beyond your local machine
Find-and-replace over files on your local machine is one thing, but there are situations where you'll need to apply a transformation across a universe of code that exists beyond your local files.
If you're working in a company, this might be something like adopting a consistent logging standard across all services in your application. If you're working in open source, this might be updating all the callers of a deprecated library function that has hundreds of downstream dependencies. In either case, the trivial becomes intractable at a large enough scale.
This problem is widespread, especially across large software organizations, and will only increase in severity in the coming years as the interdependent universe of code continues to expand.
Google calls it LSC (Large-Scale Changes) and devotes an entire chapter to it in the "flamingo book", Software Engineering at Google. Various other names we've heard include "large-scale refactoring", "large-scale codemods", "code shepherding", and "code change campaigns". Here we call them, simply, "campaigns".
The anecdotes are startling. Inside some organizations, even small campaigns can take months or even years to execute. Google has invested millions of dollars to create the internal dev infrastructure to enable campaigns to be completed tractably. Many other development organizations have created tools in the same vein, but they typically cannot afford to invest as much into these tools as Google can. These tools are usually specific to the organization that created them and rarely released publicly.
Campaigns
Note: Campaigns have evolved since this post was written, and we now call them batch changes. See [our docs](https://docs.sourcegraph.com/batchchanges) for the latest._
After hearing the same thing over and over again from different development teams, we decided to try to build a general solution for this hairy problem of large-scale code transformation. Starting in Sourcegraph 3.15, you can initiate and execute campaigns in Sourcegraph. Here's an example:
Suppose your organization has decided it wants to standardize error handling across your
codebase. In particular, you want to use wrapped errors in
Go code. This means you want to ensure that instances of fmt.Errorf use the %w format verb,
rather than %s.
Without a campaign shepherding tool, this would involve cloning down all your repositories one-by-one, running a find-replace script locally, manually pushing up a branch, and opening a pull request for each repository affected by the change. That's a lot of tedious repetition that can occupy multiple days of your time.
Here's how you'd do that in a campaign:
-
Create a JSON file named
wrapped-errors.action.jsonwith the following contents:{ "scopeQuery": "repo:^github.com/sourcegraph/ fmt.Errorf", "steps": [ { "type": "docker", "image": "comby/comby", "args": [ "-in-place", "fmt.Errorf(\":[head]%s:[tail]\", err)", "fmt.Errorf(\":[head]%w:[tail]\", err)", "-matcher", ".go", "-d", "/work" ] } ] }The
scopeQueryfield selects the set of repositories to run the change over. Thestepsfield specifies a sequence of commands or Docker containers to run over each repository. In this case, we are using the Comby Docker container to find all instances offmt.Errorfthat end in, err)and have%sin the format string, and replace the%swith%w. - Using the
srcCLI, runsrc actions exec -f wrapped-errors.action.json -create-patchset. This will clone down each repository to a sandbox, apply the transformation, and upload the patchset to Sourcegraph. It will also print a link you can click to turn the patchset into a campaign. -
After clicking the link to create a campaign, enter in the title and description of your campaign. Click
Create draft.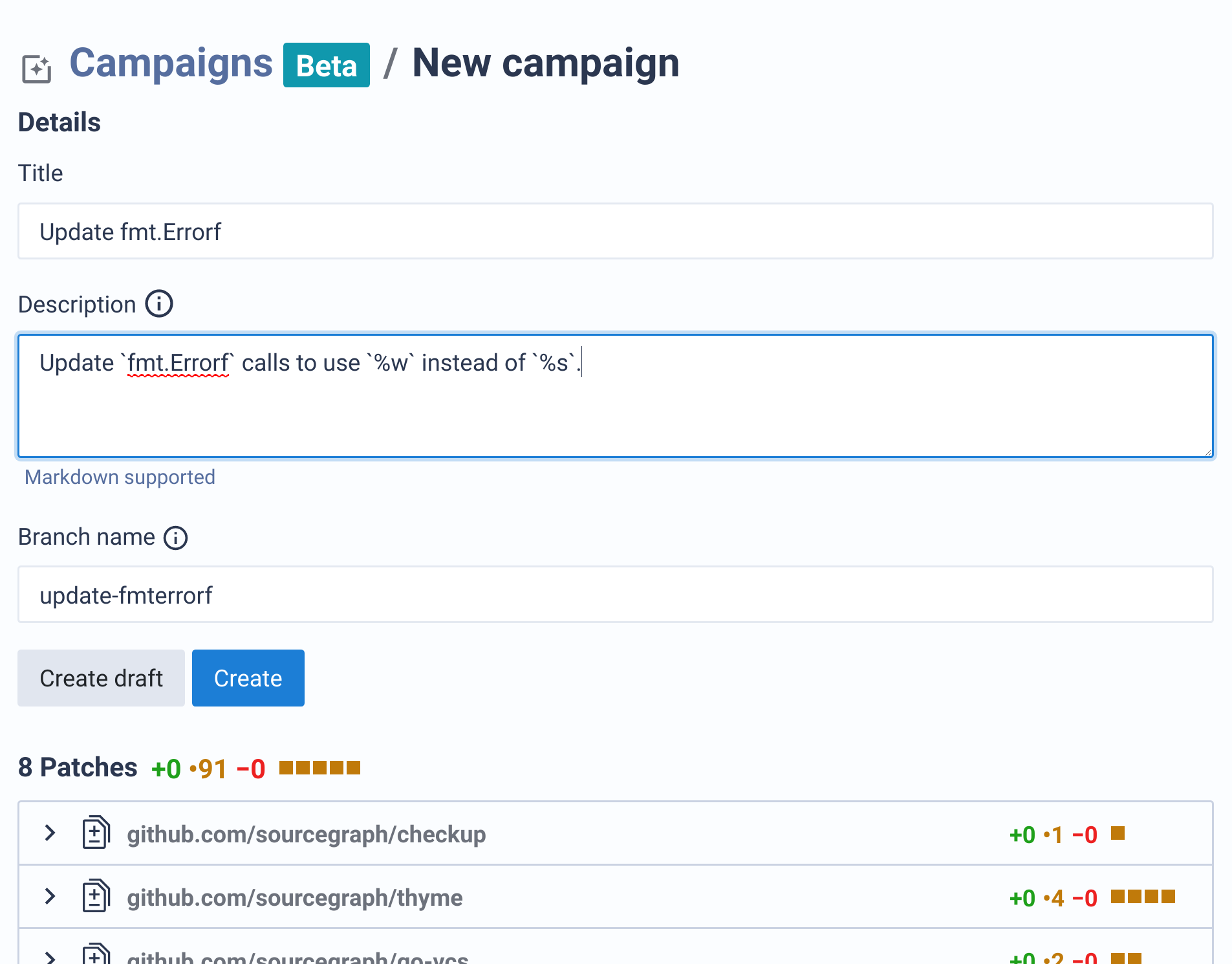
-
Examine each pull request and click
Publishafter you've verified this proposes the desired change in each repository.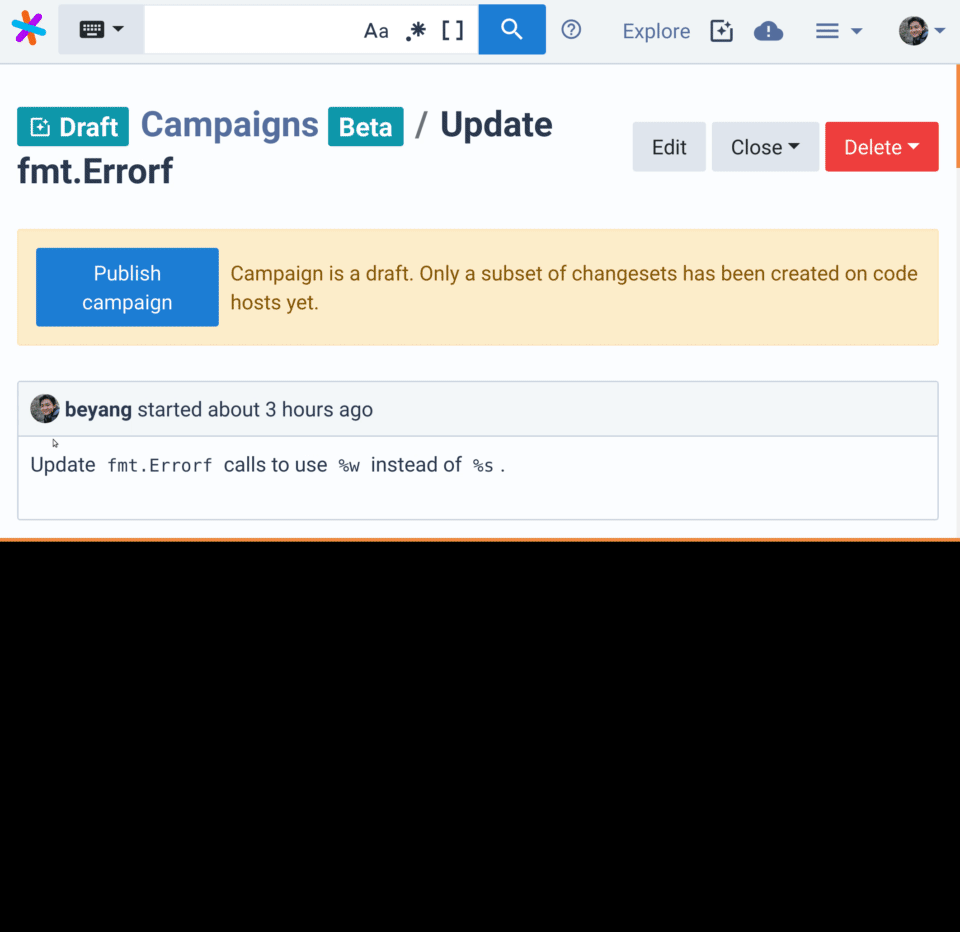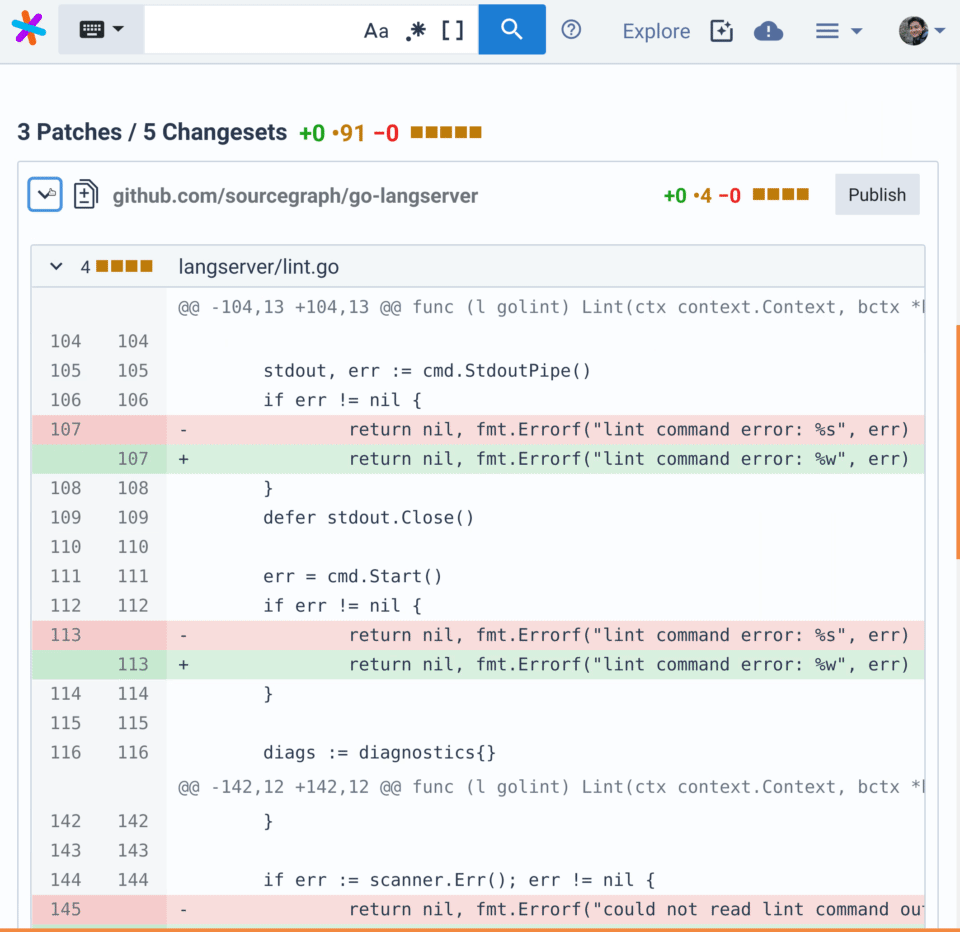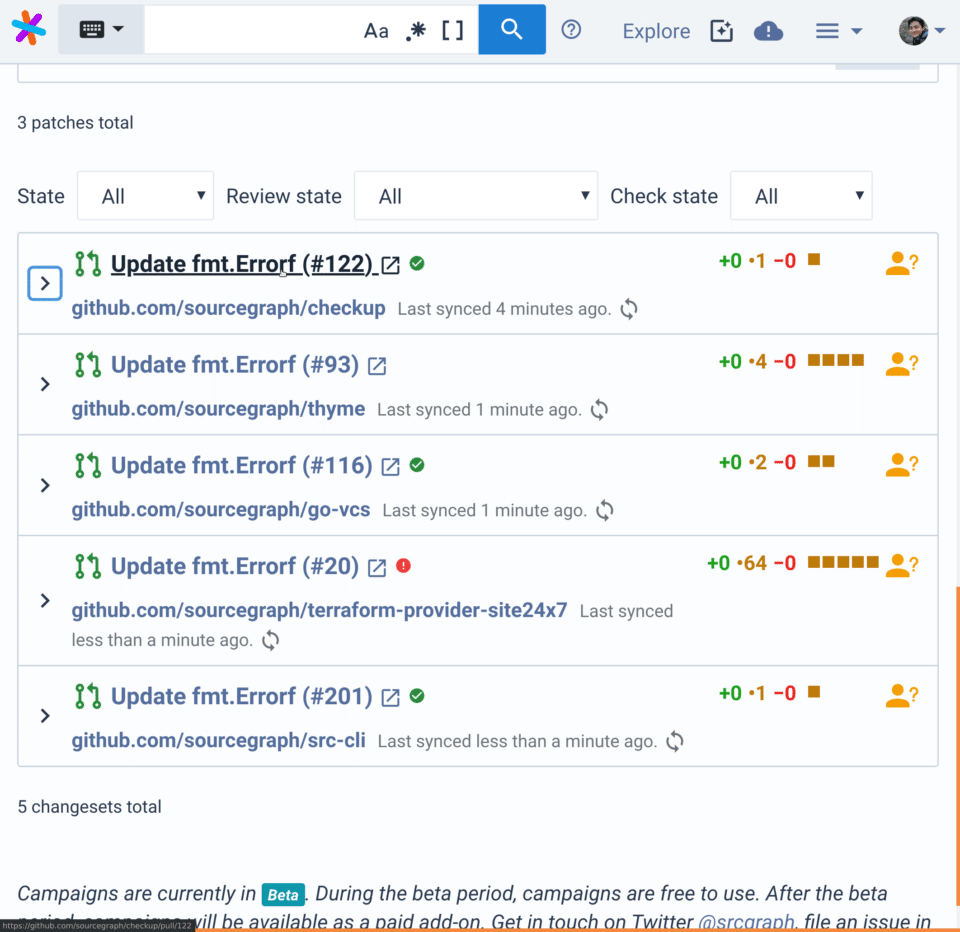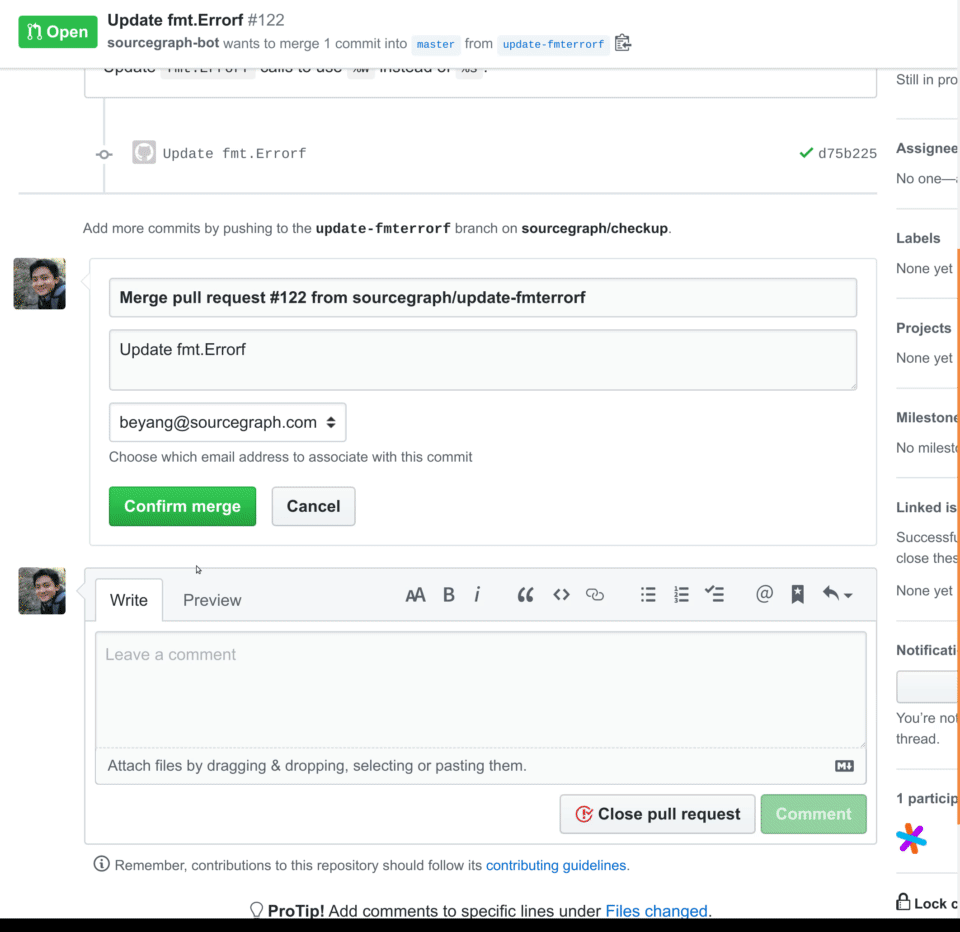
- From Sourcegraph, you have a single dashboard where you can monitor the progress of all pull requests in this campaign.
In the example above, we used Comby, because that was the simplest thing to use, but campaigns
support any find-replace tool that can be run as a local command or Docker container. Comby,
Codemod, grep, sed, and any custom script are all fair game.
Campaigns are currently in beta, available in Sourcegraph versions 3.15 and later. Read the Campaigns documentation to learn more.
Further reading
If you're interested in learning more about the tools covered in this post, here are some useful resources:
-
Regular expressions
- RegexOne, an interactive tutorial
- An Introduction To Regular Expressions from Digital Ocean
-
grep -
sed- Guide to sed basics from Digital Ocean
- Sed - An introduction and Tutorial by Bruce Barnett
-
Keyboard macros and multiselect
- Codemod
-
Comby
-
Campaigns
-
I say "most commonly used", but fluency with regex is by no means ubiquitous. You can graduate from a four-year computer science program without writing a single regex. I knew one engineer who had more than a decade of experience and was a contributor to several prominent open-source projects, but viewed regex as a foreign language.
↩ -
↩$1is sometimes used rather than\1in the replacement syntax. Check the documentation to determine which is supported in your editor. -
"grep" stands for "global regular expression print".
↩ -
"sed" stands for "stream editor"
↩ -
There are cases where this regex won't work. For example,
↩errorutil.Handler(foo(bar))orerrorutil.Handler(foo(bar(baz))). In general, any pattern that requires handling nested delimiters cannot be fully expressed in regex. Practically speaking, this isn't a dealbreaker, because you can often come up with a regex where the edge cases it doesn't handle properly don't exist in the code you're modifying. However, coming up with such a regex can be quite annoying. If you're interested in learning about a pattern language that eliminates this expressivity problem, jump to the section on Comby. -
If you're fairly inexperienced with the Unix command line, you can try viewing the one-liner on explainshell.com.
↩ -
Another complicating factor is that there are multiple implementations of
↩grepandsedthat have slightly different behavior and are defaults on different systems. macOS by default uses the BSD variants ofgrepandsedwhile Linux uses the GNU variants. The GNU and BSD variants don't support the same sets of flags and positional arguments, sogrepandsedinvocations that work on Linux often break on macOS or vice versa. You can get around this by installing the non-default variant on either system, but this, of course, adds complexity. -
Two other Unix commands that are often used in conjunction with
↩grepandsedarefindandawk. For brevity's sake, we don't go into them here. -
Other
↩grepalternatives includeack,ag, andsack.git-grepisgrepbut only over files known togit(and for this reason, it's often much faster). Personally, I've found ripgrep to be the fastest grep alternative, generally speaking. -
It just so happens that Comby was created by a fellow Sourcegrapher, the brilliant Rijnard van Tonder, as part of his Ph.D. research. Part of the reason he joined Sourcegraph was to put his research into practice among as many developers as possible. If you also have a fantastic new idea that can improve the productivity of many developers, shoot me a message at beyang@sourcegraph.com!
↩